Voltar aos projetos
Projeto 01
Pipeline de Anonimização na Nuvem
Pipeline de anonimização de dados com sincronização incremental e migração para a nuvem.
Python 3.13
PostgreSQL
Neon Cloud
psycopg2
Faker
pandas
Task Scheduler
Power BI
01 — Resumo
O que foi construído
Problema
Dados comerciais reais — clientes, vendas, fornecedores — não podem ser expostos em portfólios sem risco de violação de privacidade e LGPD.
Solução
Pipeline Python que lê o banco local, aplica anonimização determinística por tipo de dado e migra para Neon Cloud com sync incremental diário.
Resultado
Banco cloud público com dados 100% fictícios, JOINs funcionando, Power BI conectado e zero risco de exposição de dados reais.
1.25M
Registros de vendas
12+
Tipos de anonimização
100%
Integridade referencial
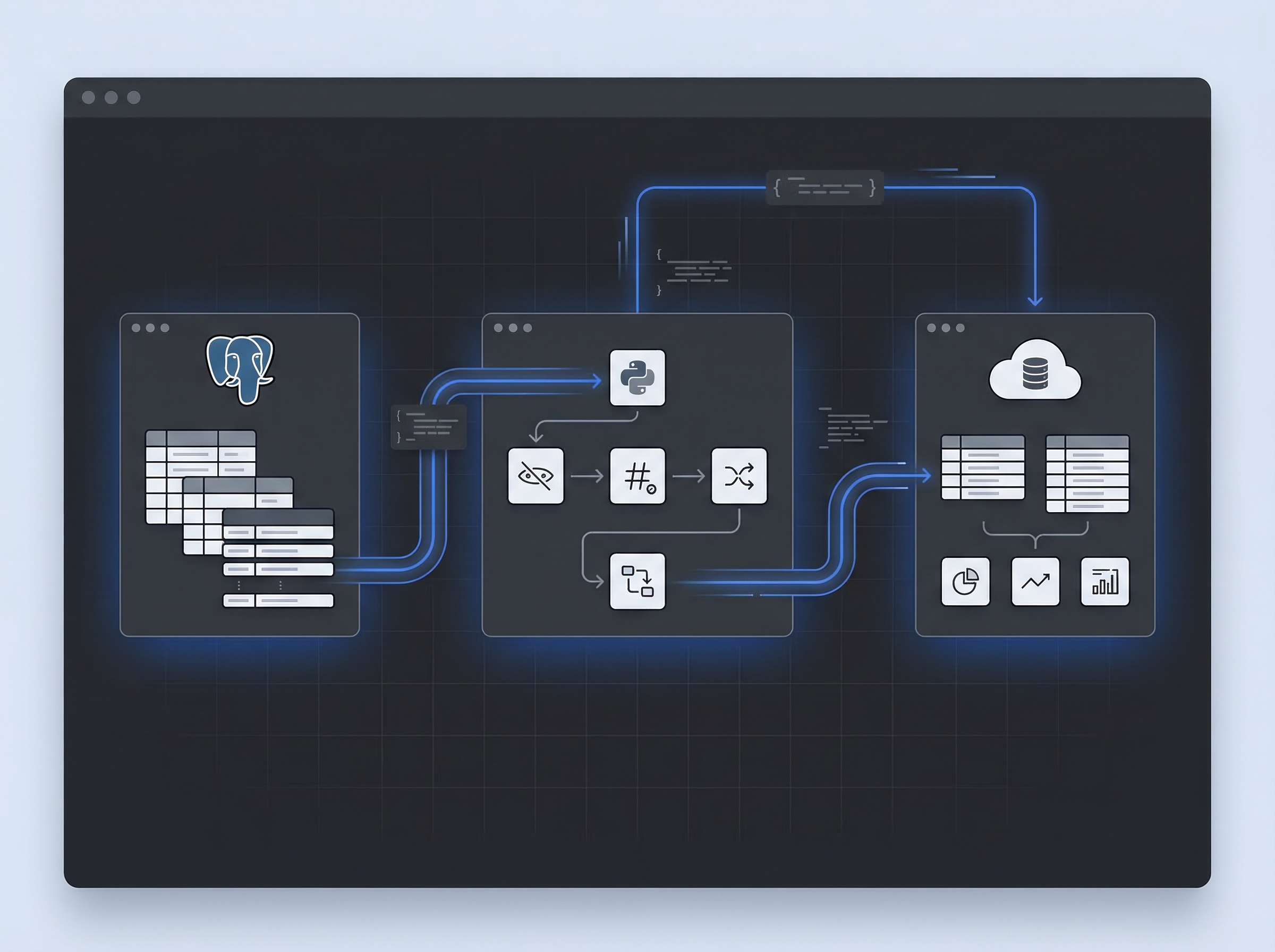
02 — Arquitetura
Fluxo da solução
┌────────────────────────┐ ┌──────────────────────────┐ ┌──────────────────────────┐
│ │ │ │ │ │
│ PostgreSQL Local │──────▶│ Pipeline Python │──────▶│ Neon Cloud │
│ (dados reais) │ │ (anonimização) │ │ (dados fictícios) │
│ │ │ │ │ │
│ IP: 120.0.0.x │ │ secrets.toml │ │ ep-wild-bread.neon.tech│
│ db: bi_redebiz │ │ + Faker + hashlib │ │ db: rerissonDB │
└────────────────────────┘ └──────────────────────────┘ └──────────────────────────┘
│
┌─────────────┴──────────────┐
│ Task Scheduler (diário) │
│ sync_vendas.py → log.txt │
└────────────────────────────┘
base_migracao.py
Módulo central com toda lógica de anonimização, conexão, detecção de colunas sensíveis e inserção em lotes. Importado pelos 4 scripts individuais.
migrar_*.py (×4)
Scripts individuais por tabela com configuração declarativa: quais colunas subir e como anonimizar cada uma. ~30 linhas cada.
sync_vendas.py
Sync incremental: busca MAX(data_emissao) no Neon e traz apenas registros novos do banco local. Executa em menos de 30 segundos.
executar_sync.bat
Agendador Windows Task Scheduler com log automático em sync_log.txt. Registra data, hora, registros inseridos e duração de cada run.
03 — Código
Como funciona na prática
Três decisões técnicas que fazem o pipeline funcionar de forma robusta e extensível.
Anonimização determinística via hash MD5
O mesmo valor original sempre gera o mesmo valor fictício — garantindo que JOINs entre tabelas funcionem no Power BI sem tabelas de mapeamento externas.
def _hash_seed(valor) -> int:
h = hashlib.md5(str(valor).encode()).hexdigest()
return int(h[:8], 16)
# Mesmo CNPJ original → sempre mesmo CNPJ fictício
def gerar_cnpj_ficticio(original, apenas_digitos=False):
chave = f"{original}_d" if apenas_digitos else str(original)
if chave not in _cache_cnpj:
seed = _hash_seed(original)
d = str(seed % 10**14).zfill(14)
_cache_cnpj[chave] = d if apenas_digitos else f"{d[:2]}.{d[2:5]}.{d[5:8]}/{d[8:12]}-{d[12:14]}"
return _cache_cnpj[chave]
Detecção automática de colunas sensíveis
Três níveis de prioridade: colunas preservadas (chaves FK) → match exato no nome → match parcial como fallback. Nenhuma coluna sensível escapa.
# Prioridade 1: chaves de relacionamento — NUNCA anonimizar
COLUNAS_PRESERVAR = {"vendedor", "cliente", "mercadoria", "fornecedor", ...}
# Prioridade 2: match exato no nome da coluna
MAPA_EXATO = {
"cnpj": "cnpj",
"raz_social": "empresa",
"cidade": "cidade",
"valor_liq": "financeiro",
"data_cadastro": "data",
}
# Prioridade 3: match parcial como fallback
MAPA_PARCIAL = {"email": "email", "valor": "financeiro", ...}
Sync incremental — vendas diárias
Apenas registros novos são enviados. Executa em menos de 30 segundos para cargas diárias típicas.
def main():
# 1. Busca a última data no Neon
ultima_data = SELECT MAX(data_emissao) FROM vendas
# 2. Lê apenas os novos do banco local
novos = SELECT * FROM vendas
WHERE data_emissao > ultima_data
ORDER BY data_emissao
# 3. Anonimiza com as mesmas regras da migração inicial
novos_anon = processar_vendas(novos)
# 4. Insere no Neon em lotes de 1000
inserir_neon(conn_neon, novos_anon)
# → Log gravado em sync_log.txt
04 — Stack
Tecnologias utilizadas
Core
-
Python 3.13
Pipeline principal
-
PostgreSQL 15
Banco de origem local
-
Neon Cloud
Banco destino público
Bibliotecas
-
pandas 2.x
Manipulação de DataFrames
-
Faker (pt_BR)
Geração de dados fictícios
-
psycopg2
Driver PostgreSQL
Infraestrutura
-
Power BI
Visualização conectada ao Neon
-
Task Scheduler
Sync diário agendado
-
secrets.toml
Credenciais fora do código
Código aberto
Quer ver o código completo?
Todos os scripts estão disponíveis no GitHub com documentação detalhada de cada módulo.
Available for remote opportunities 🌎
Voltar aos projetos